加齢に伴い脳の動脈硬化が進むと脳血管障害が増加し、意識障害や運動麻痺,あるいは言語障害などの後遺症が問題となります。このため、脳の損傷により本来の機能がどのように障害されるかのメカニズムを明らかにすることは、リハビリテーションのみならず脳機能の理解のためにも非常に重要な意味を持ちます。現在、当グループでは、様々な手法を用いて人間の認知機能とその障害に関する研究を進めています。ここでは特に言語機能に焦点を当て、それをコンピュータに模倣させることにより、人間が行う言語処理の仕組みや特定の言語障害が生じるメカニズムを明らかにしていくというアプローチを紹介します。
脳損傷によって生じる言語障害の一つに「失読症」があります。これは、書かれた文字列を正しく読むことが出来ない症状で、読み誤りのパターンからいくつかの種類に分類できます。
日本語の文字表記法には漢字と仮名がありますが、表層性失読と呼ばれる症例は、主に漢字の読みに強い障害を示します。しかし、漢字には読み方がいくつかあり、「成功」、「保留」のように各文字の読み方が典型的な単語(以下、典型語)と、「成就」、「書留」のように、読み方が稀な単語(非典型語)とがあります。表層性失読は、特に非典型語に障害が強く現れます。
一方、音韻性失読と呼ばれる症例は、普段見慣れない文字の並びの読みに障害が現れます。例えば、「セイコウ」、「セイトメ」といったカナ文字の並びは、普段目にすることはほとんどありません。しかし、前者は確かに見慣れませんが、音的には聞きなれた同音語です。後者の方は見慣れませんし、音的にも聞きなれない非語です。音韻性失読は、特にこの非語の読みに強い障害が現れます。
それではこれらの失読症状は、どのようなメカニズムによって生じるのでしょうか?この問題を検討するに当たって、まず、健常成人がどのように語を読んでいるかのモデルを作りました。このモデルはシミュレーション・モデルと呼ばれるもので、実際にコンピュータ上で動かすことにより、その振る舞いを見ることができます。
近年、コンピュータの目覚しい進歩により、人間の認知機能をコンピュータ上で構築したシステムに模倣させることが可能になってきました。ここでは特に、実際の脳に近い構造と動作様式を持つ脳型情報処理システムであるニューラル・ネットワークに注目します。ニューラル・ネットワークは、神経細胞を模倣したユニットと呼ばれる処理要素を結線により多数組み合わせて回路網状にしたシステムで、これを利用することにより、日本語単語を読むモデルを作りました(図1)。
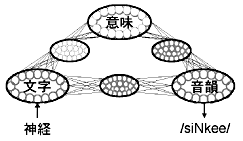
図1 日本語を読むニューラル・ネットワーク・モデル
小さい丸がユニット、楕円がユニットの集合を表しています。単語の文字,音韻、意味を表すユニット集合が、結線を通して情報をやり取りすることにより処理が進みます。ネットワークの出力として/ /で囲んだものは、入力された単語の発音を表します。なお、例としてあげた「神経」を平仮名表記すれば「しんけい」ですが、その発音は/siNkei/ではなく/siNkee/となります。
モデルは、単語の文字、音韻、意味をそれぞれ表現するユニットの集まりと、各ユニットをつなぐ結線とから構成されています。ユニットは結線を通して他のユニットからの重み付き信号を入力として受け取ります。この入力信号がユニット内で加算され、ある閾値を超えた場合、そのユニットは活性化し、他のユニットへ結線を通して信号を送ります。
図2は、図1の底辺部分(文字列からその音韻を計算する部分)だけを取り出し、処理の過程を具体的に示したものです。モデルの文字ユニット集合上にビットマップ・パターンを入力すると、全てのユニットが結線を介して情報をやり取りすることにより、音韻ユニット集合上に音素記号様に表現された読みを出力します。こうして読むことができる単語は一つだけではなく、モデルは学習機能によって約5,000の漢字語と約2,000のカタカナ語、計7,000語を読むことができるようになりました。
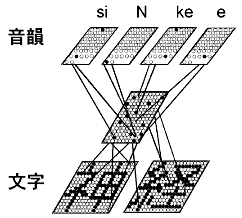
図2 コンピュータ上に構築された、文字列からその音韻を計算するモデル
図1の底辺部を具体的に示したもの。ビットマップで表現された「神経」という文字列を入力すると、結線を介してユニット間に情報が伝達され、最終的に/siNkee/という音素記号様に表現された音韻を出力します。
興味深いのは、モデルが人間と同じような読みの振る舞いを見せることです。モデルが正しい読みを出力するための計算にかかる時間は、よく目にする単語や典型語ほど速くなりました。またモデルは単語(例、セロハン)だけでなく、学習していない非語(例、セイコウ、セイトメ)も読むことができますが、単語に比べて計算時間が遅くなりました。これらは健常成人が単語や非語を読む際に示す音読特徴とよく対応しています。このようにモデルは、人間の読み方をうまく模倣することができました。
次に、構築したモデルの一部を壊すことによって各失読症例の示す読み誤り特徴を再現し、それぞれの障害が生じるメカニズムを検討します。つまり、脳損傷に対応した状況を人工的に作り出すわけです。しかし、やみくもにモデルを壊すのではなく、症例ごとの臨床的、実験的なデータを検討した上で、モデル上で壊すべき部位を特定していきます。
多くの臨床データから、意味理解に障害を持つ症例では、非典型語に強い障害を示す表層性失読の症状が出現することが分かっています。例えば、リンゴを見せた後、ナイフとスプーンから関連の深い方を選ぶような意味理解課題の成績が悪いという症例に、前述のごとく非典型語の読みに強い障害を示す表層性失読が見られるわけです。さらに、意味理解の障害が重度になるほど非典型語の読みの成績が低下することから、どうやら、表層性失読例は、意味を処理する機能に障害を持っているのではないかということが推測できます。そこで図1の意味から音韻への結合が全て切断されたと想定し、意味からの情報が音韻へ行かないようにすると、モデルは表層性失読症例と同じように、非典型語の音読成績が特に低下しました。
次に音韻性失読症例を見てみると、実はほとんどの症例が、音読課題のみならず、/ka/と/mera/を聞いて/kamera/と言わせるといった読みに関係ない課題でも、刺激が非語の場合に困難を示すという報告があります。従って、これらの症例は、音韻自体に何らかの障害があると推測できます。そこで図1の音韻部分に関与している結線を切断すると、モデルは単語、同音語(セイコウ)、非語(セイトメ)の順に音読成績が悪くなり、音韻性失読症例と同じ読み誤りを示すようになりました。
図1に示したニューラル・ネットワークが健常成人の音読特徴を模倣できるだけでなく、失読症例のデータから予測される機能部位を壊すことでそれぞれの症状と同様の読み誤りを再現できるという結果は、この脳型情報処理システムが人間の読みに関する機能モデルとして妥当であることを示しています。このモデルは、
という利点があり、人間の認知機能の仕組みを考察する際、非常に有用な道具となります。私達は、特に(3)の特徴- 脳損傷に相当するダメージをモデルの好きな場所に好きな強さで与え、モデルの振る舞いを繰り返し観察するといったことが容易に実現できる- が、リハビリテーションといった医療場面に有用であると考えています。つまり、一度損傷を受けたモデルに対して、あらためて語の読みを再学習させる手法を検討することにより、言語聴覚士が失読症例に対して行う言語訓練に何らかの方法論的な示唆を与えることができると期待しています。これと関連して、どの程度の損傷ならば、どこまで回復が可能なのかを系統立ててシミュレーションすることにより、個々の症例の予後が予測できるようになるかも知れません。今後は、これらの応用可能性を考慮しつつ、さらにモデルを洗練させていきたいと考えています。


